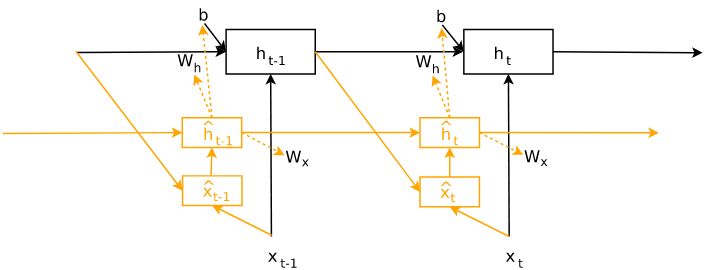
有一个有趣的地方值得注意,在HyperLSTM细胞不那么活跃的时候,单词的类别看起来更容易预测。例如,在第一个例子中,Microsoft Windows是在Micros之后的一个或多或少静止的网络上生成的。在第二个例子中,elections in the early 1980s(1980年代早期的大选)是由一个相对不变的主LSTM生成的,但就在1980s之后,HyperLSTM细胞突然苏醒了,决定在开始讨论savage employment concerns(残酷的就业问题)前给主LSTM模型一点震动。从某种意义上说,当生成式模型生成序列的时候,HyperLSTM细胞持续生成生成式模型。
这样动态生成生成式模型的元能力看起来非常强大,事实上,我们的HyperLSTM模型能够击败之前最先进的字符级别预测数据集基准,例如Character-Level Penn Treebank和Hutter Prize Wikipedia(enwik8)。在未使用动态评估的前提下,我们的模型在两个数据集上分别取得了1.25 bpc和1.38 bpc的成绩(27-Sep-2016),超过了之前的记录1.27和1.40(10-Sep-2016)。
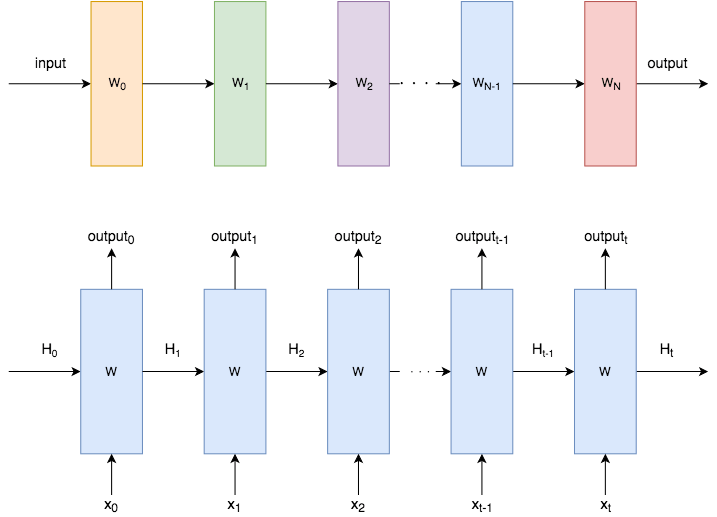
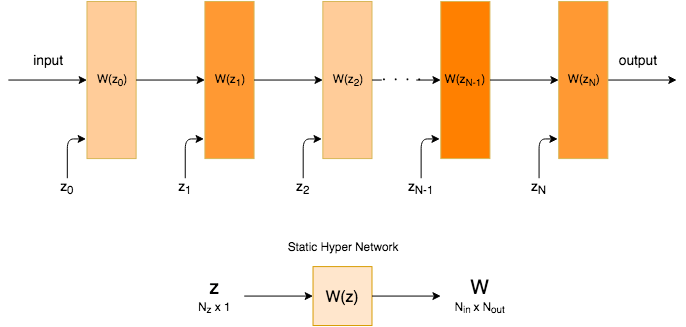
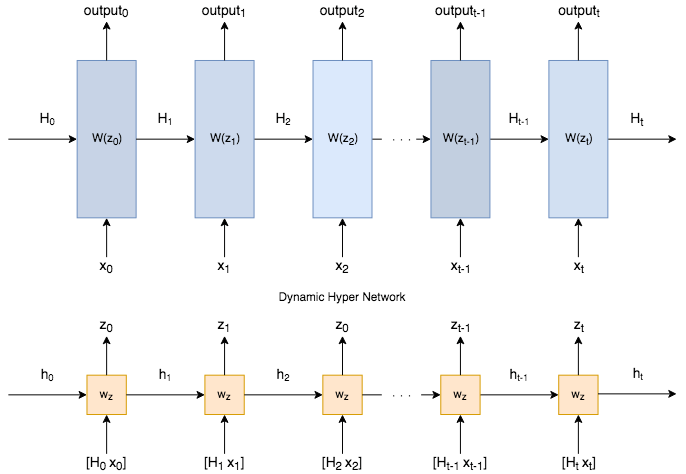
考虑到机器学习研究领域的发展速度,几周之后,其他人大概就会超过这些最先进的数字,更别提ICLR 2017的死线快到了。事实上,我并不真的认为在某个文本数据集上击败最先进的记录和探索这样的多层动态模型抽象下的动态模型同等重要。我觉得以后人们会更少关注架构设计,转而关注两个方向,或者是应用侧,或者是基础的构建模块侧。我喜欢我们的方法的地方是我们事实上创建了一个称为HyperLSTM的构建模块,在TensorFLow的用户看来,和普通的LSTM模块很像。HyperLSTM对现存的TensorFlow代码而言是即插即用的,就像替换RNN、GRU、LSTM细胞一样,因为我们将HyperLSTM实现为tf.nn.rnn_cell.RNNCell的一个实例,称为HyperLSTMCell(这包括整个系统,别和HyperLSTM细胞混淆了)。
生成生成式模型



 发表于 2022-12-2 19:09:47
发表于 2022-12-2 19:09:47