|
|
人工神经网络(artificial neural networks, ANN)被广泛应用于非线性函数逼近。一个 ANN 是由相互连接的单元组成的网络,这些单元拥有神经系统主要部分的神经元的某些性质。ANN 具有悠久的历史,最近深层的 ANN (深度学习)在一些机器学习系统,包括强化学习系统中展现了惊人的成果。
图 1 展示了一个普通的前向 ANN,这种网络在网络内部没有环,也就是在网络中没有一个单元的输出可以影响自身的输入。图中网络的输出层有两个单元,输入层有四个单元,同时有两个“隐层”:网络中既不是输入也不是输出的层。每条连接的边有一个实值权值。这些权值大致相当于真实神经系统中突触连接的角色。如果一个 ANN 中至少有一个环,那它就是一个循环神经网络,而不是前向神经网络。虽然前向和循环 ANN 在强化学习系统中都会使用,但在这里我们仅以简单的前向神经网络为例来进行探讨。
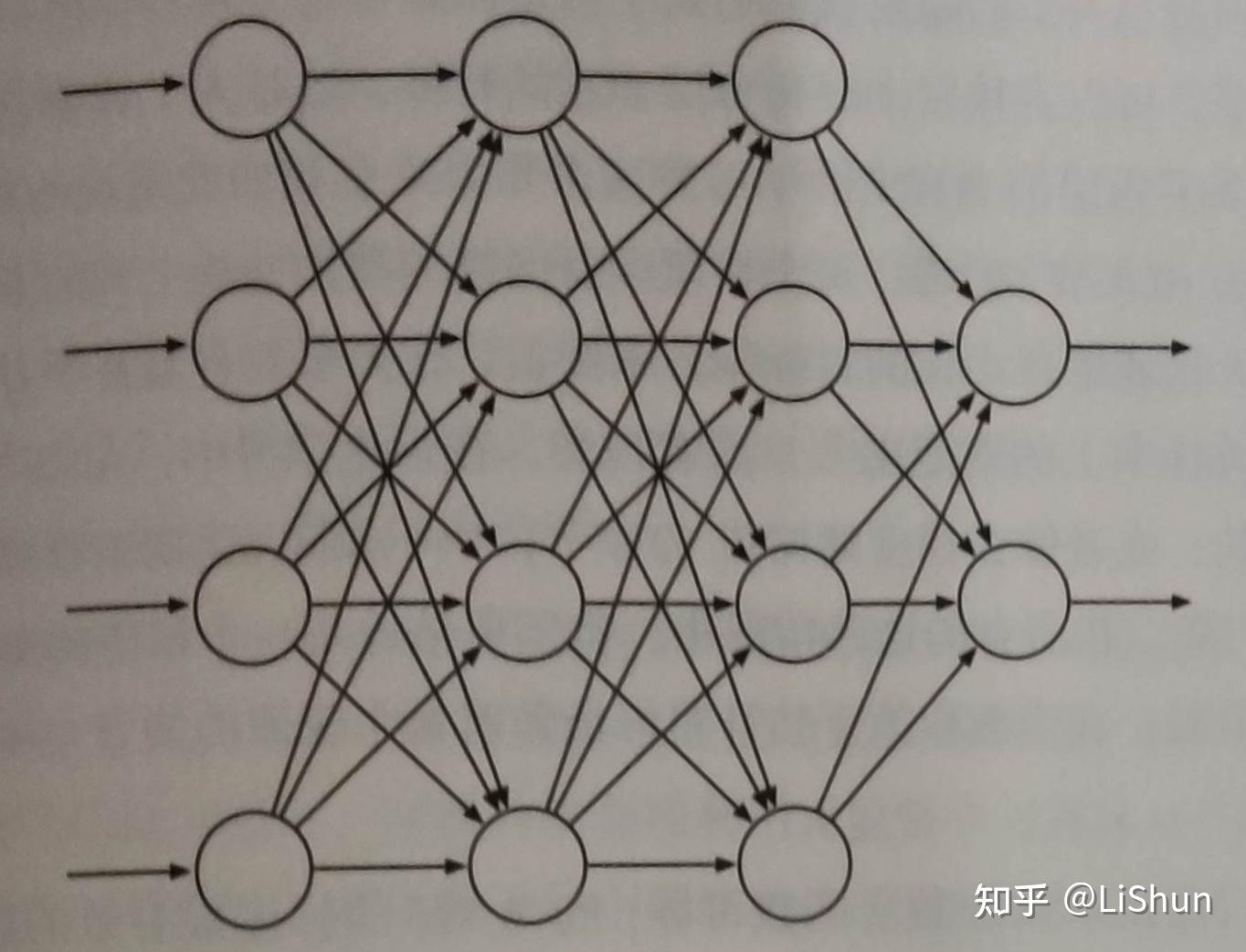
图 1
ANN 的计算单元(图 1 中的圆圈)一般是半线性的,也就是它首先求输入信号的加权和,然后再对结果应用非线性函数,称作激活函数,最后得到单元的输出(或称“激活”)。有许多不同的激活函数,它们一般都是 S 形函数,或 sigmoid 函数,例如 logistic 函数 f(x) = 1 / (1 + e^{-x});有时也使用非线性整流函数 f(x) = \max (0, x)。或是阶梯函数,例如当 x \geq \theta 时, f(x) = 1,否则为 0;通过使用阈值 \theta 可以使得计算单元的输出是二值的。网络的输入层单元有些不同,它们的激活依靠从外部来的值,这些值也是该网络去近似的函数的输入值。
前向 ANN 的每一个输出单元的激活是网络输入单元的激活的非线性函数。网络中的连接权值就是函数的参数。一个没有隐层的 ANN 只能表示一小部分可能的 “输入-输出” 映射函数。然而,如果 ANN 拥有一个隐层,并且这个隐层包含足够多数量的 sigmoid 激活单元,则这个 ANN 可以在网络输入空间的一个紧凑区域内以任意精度逼近任意的连续函数(Cybenko, 1989)。对于其他满足适当条件的非线性激活函数,此结论也成立。注意,非线性在这里很重要:如果一个多层 ANN 的所有单元的激活函数都是线性的,那么这个网络等价于一个没有隐层的网络(因为线性函数的线性函数仍然是线性的)。
尽管存在上述单隐层 ANN 的 ”泛逼近“ 性质,但实践和理论都表明,对于许多人工智能任务所需要的复杂函数而言,采用层次化的抽象可以使得逼近过程更容易。在这里,高层的抽象是许多低层抽象的层次化组合,例如多隐层的 ANN 深度结构(更多综述参见 Bengio, 2009)。深度 ANN 的各层逐步计算 ANN 网络的 ”原始“ 输入的越来越抽象的表示,每一个计算单元提供了整个 ”输入-输出” 网络函数的层次化表示中的一个特征。
这样一来,训练 ANN 的隐层就成为对于给定问题自动发现特征的一种方法。它不需要人工设计的特征,可以直接自动获得分层表示的特征。这是人工智能领域的一个持续的挑战,也是为什么多隐层的 ANN 的学习算法多年以来受到如此重视的原因。ANN 一般用随机梯度下降法训练。每个权值朝着网络的整体性能上升的方向调整,性能一般用一个需要最大化或者最小化的目标函数来衡量。在大多数监督学习中,目标函数一般是带标注的训练样本上的期望误差,或者损失。在强化学习中,ANN 可以使用 TD 误差来学习价值函数,或者像在梯度赌博机中一样最大化期望收益,或者使用策略梯度算法。在所有的这些情况中,都需要估计每一个权值的变化如何影响网络的整体性能,也就是,在当前权值下估计目标函数对每个权值的偏导。梯度是所有这些偏导组成的向量。
求包含隐层(假设单元的激活函数可导)的 ANN 的梯度最有效的是反向传播算法,它包括交替的前向和后向传播过程。前向过程通过给定网络输入单元的当前激活来计算网络中每一个单元的激活输出。在每个前向传播过程后,反向传播过程可以高效地计算每个权值的偏导(和其他随机梯度学习算法一样,这些偏导组成的向量是真实梯度的估计)。在后面的章节中,我们讨论利用强化学习原理而不是反向传播算法来训练带隐层的 ANN。这些方法没有反向传播算法高效,但是它们可能更像是真实神经系统的学习过程。
对于包含 1 到 2 个隐层的浅层网络,反向传播算法可以得到很好的结果,但是对于更深的 ANN 可能并不奏效。实际上,训练一个 k+1 层网络的效果可能比 k 层网络的效果还要差,尽管更深的网络可以表示浅层网络可以表示的所有函数(Bengio, 2009)。解释这种现象不是很容易,但是其中有些因素是很重要的。首先,深度 ANN 中拥有大量的参数,这使得它很难避免过拟合的问题,也就是,网络很难正确泛化到训练数据中没有的情况。其次,反向传播算法在深度 ANN 中效果不是很好,因为反向过程中计算的偏导在向输入层传播的过程中要么很快减小使学习变慢,要么快速变大使学习不稳定。现在深度 ANN 取得的一系列令人印象深刻的成果,在很大程度上源于成功解决了这些问题。
过拟合是任何函数逼近方法在有限的数据上训练多自由度函数都会遇到的问题。对于在线的强化学习,这个问题相对来说不突出,因为它不依赖于有限的训练集,但是有效地泛化依然是一个重要的问题。过拟合是 ANN 的一个普遍问题,但在深度 ANN 中由于参数量巨大,这个问题就显得尤其突出。有许多防止过拟合的方法,包括:当模型的性能开始在校验集上下降时停止训练(交叉验证),修改目标函数限制近似函数的复杂度(正则化),引入参数依赖减小自由度(如参数共享)等。
一个特别有效的防止深度 ANN 过拟合的方法是由 Srivastava、Hinton、Krizhe-vsky、Sutskever 和 Salakhutdinov(2014)提出的随机丢弃法。在训练时,网络中的单元包括对应的连接会被随机丢弃。这好比是训练了很多 “瘦身” 后的网络。在测试阶段将这些网络的结果组合在一起,是提高泛化能力的有效途径。一种有效的组合方法就是将每个单元的输出连接的权值乘以该单元在训练过程中被保留的概率(这个概率就是 1 减去随即丢弃的概率)。Srivastava 等人发现这种方法能够显著提高泛化性能。它促使每个独立的隐层单元学到的特征能够适应其他特征的随机组合。这增加了隐层单元所形成的特征的多方适用性,使网络不至于过分地关注那些罕见的样本。
Hinton、Osindero 和 Teh(2006)在如何训练深层的 ANN 方面取得了重要的进展,当时他们使用的是深度置信网络,这种网络也是层级连接的网络,和我们这里讨论的深度 ANN 很像。在他们的方法中,网络的较深层利用无监督学习算法逐层训练。逐层无监督学习使得优化是每层局部的,不依赖于整个网络整体的目标函数,这可以有效地抽取能够捕捉输入统计特性的特征。首先训练最深的层,然后固定这一层,训练第二深的层,依此类推,直到所有或者绝大部分权值都训练了。这些权值会作为有监督学习的初始权值,接下来根据目标函数利用反向传播算法继续调整权值。研究表明,这种方法的效果比随机初始化权值的效果明显要好。这种方法效果好的原因可能有很多,其中一个解释是这种方法可以把网络的权值预训练到一个比较适合梯度方法调整的区域。
批量块归一化(Ioffe 和 Szegedy,2015)是另一种可以使深度 ANN 更容易训练的技术。人们早已发现如果输入数据的值域是归一化的,那么 ANN 会更容易训练。基于这个认识,一种简单做法就是将输入变量的值域调整为均值为 0,方差为 1.深度 ANN 的批量块归一化方法将较深的层的输出在输入给下一层之前进行归一化。Ioffe 和 Szegedy(2015)使用训练样本的一个子集,或称 “小批量块”,在层与层之间进行归一化来改进深度 ANN 的学习率。
另一种适合训练深度 ANN 的方法是深度残差学习(He、Zhang、Ren 和 Sun,2016)。有时候,知道一个函数与恒等函数的差别可以帮助我们更好地学习这个函数。那么我们就可以把这个差值,或称为残差,输入给待学习的函数。在深度 ANN 中,可以将若干隐层组成一个模块,通过在模块旁边加入 ”捷径连接“ (或称 ”翻越连接“)来学习一个残差函数。这些连接将模块的输入直接送给它的输出,且没有增加额外的权值。He 等人(2016)使用相邻层带翻越连接的深度卷积网络评估了这种方法,发现它在基本的图像分类问题上的表现比没有带翻越连接的网络有极大的提升。批量块归一化与深度残差学习被同时应用在了强化学习的著名应用 ”围棋“ 游戏上。
深度卷积网络是一类典型的深度 ANN,它在包括强化学习在内的许多应用中取得了良好的效果。这种类型的网络比较适合于处理高维空间数据,比如图像。这个模型是受大脑中早期视觉信号处理工作机制的启发而建立的(LeCun、Bottou、Bengio 和 Haffner,1998).由于它的特殊结构,深度卷积网络可以直接利用反向传播算法来优化,而不需借助前面介绍的训练深层网络的各种方法。
内容来源
Sutton R S, Barto A G. Reinforcement learning: An introduction[M]. MIT press, 2018. |
|



 发表于 2022-12-10 07:22:05
发表于 2022-12-10 07:22:05