|
|
神经网络结构
- 每个神经元是 线性+激活函数 或者线性函数
- 层数 = 隐藏层 + 输出层
- 隐藏层 = 2; L1+L2
- 输出层 = 1; L3


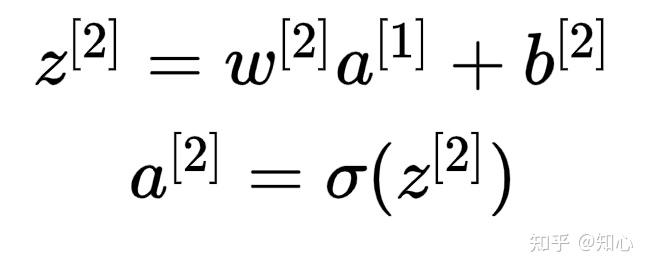
反向传播
- 最后的预测 同 实际值的损失代价函数 L(y,\hat{y})
- L 对前一层偏导;对前前一层偏导,一层一层的往前传递,一直到L1
前向传播
- 从第一层开始计算,直到输出层,得到预测值
- 前向传播求损失,反向回传损失
求参的过程
- 初始化每层的神经元的参数
- 正向传播,得到 损失L1
- 反向传播,梯度求导,更新每层的参数;从后往前,更新每一层的参数
- 再次正向传播,得到损失L2
- 反向传播,梯度求导,更新每层的参数
- 不停的重复 2-3;直到损失达到阈值或者达到训练的参数
如果参数初始化为0
- 同一层的神经元具有对称性,计算结果一致
- 参数应该随机选择,注意梯度爆炸 & 梯度消失的情况
梯度爆炸 & 梯度消失
- 假设有 m 层神经元,每层神经元2个,输出为 \hat{y} ,损失为 L(y, \hat y )
- f : 激活函数 ; f_{i} 为第i层输出
- f_{i+1} = f(f_i * w_i +b_i)
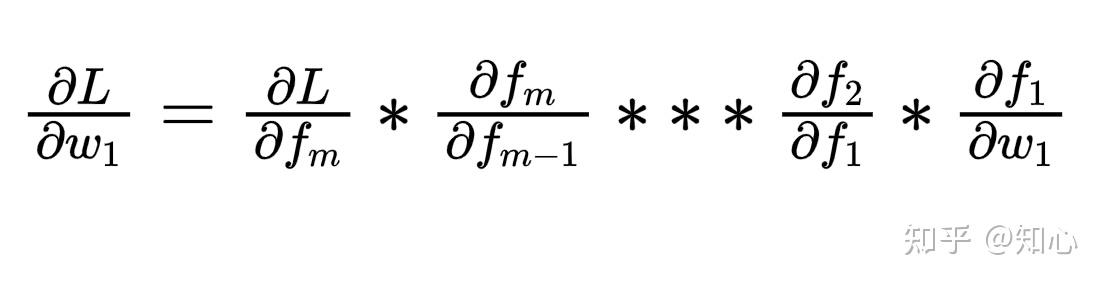
- \Delta w = 偏导;
- 如果层数多,且 \frac{\partial f_k}{\partial f_{k-1}} 偏导>1 ,指数级增长, \Delta w 趋于无穷大 ---> 梯度爆炸
- 如果层数多,且 \frac{\partial f_k}{\partial f_{k-1}}偏导 < 1, 指数级降低,消失, \Delta w 趋于 0 ----> 梯度消失
影响因素
不同的激活函数,通过设置不同的 w 初始化,可以解决 梯度爆炸和消失问题
梯度检验
目的:神经网络,确认梯度计算正确
自定义 x, \varepsilon = 0.01 利用导数的计算原理
\frac{f(x + \varepsilon ) - f(x-\varepsilon)}{2 * \varepsilon} : 近似 f(x) 的导数,双侧误差更低
\frac{f(x ) - f(x-\varepsilon)}{ \varepsilon} : 不使用这个的原因是 误差级数

将各层的 dw 组合为一个大的矩阵,构成 J(dw1,dw2,,,,)
多大的误差认为计算正确
mini batch
- BGD : batch = 全量样本的 mini batch
- SGD : batch = 1个样本的 mini batch
- 每次迭代 1个样本,计算快,但是效率低,未利用向量的计算
计算流程
- 假设有m 个样本,每batch = 1000 ,可分为 k=m / 1000 个批次
- 一次 epoch = 一次训练集遍历
- 迭代 epoch :
- 迭代 k 批次,第 i 批次 样本
- 正向传播,得到 i 批次 样本的预测值
- 计算 i 批次的 损失 L
- 反向传播,更新每层的系数
- 迭代停止条件:
- 迭代次数 = epoch * k
参数设置
- epoch 设置多大合理
- batch 设置多大合理
- 标准以 损失值下降快为准,画代价函数图 x=迭代次数;y: 损失值
- batch 量的样本,是否可以放入内存中,加快计算速度;以 2^n 为标准设置
动量梯度下降
- 针对梯度下降加快迭代的优化,即反向传播的基础上,对 w,b 的优化
- 使用了指数滑动平均原理
- 梯度下降法中,迭代点的更新方向由当前的负梯度方向和上一次的迭代更新方向加权组合形成
- Vw_t : 近似为 \frac{1}{1-\beta} 个 w 的 均值
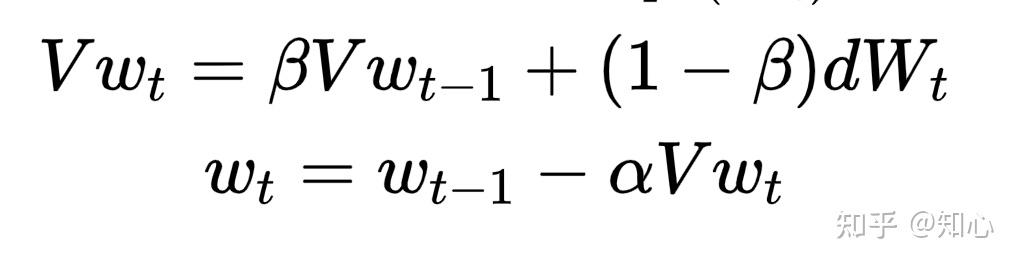
优点:
- 加快迭代速度
- 限制为 当前梯度方向和上一次的迭代更新方向相同
- 垂直方向震荡小
- 水平方向加快迭代
- 迭代平滑
RMSprop
- Root Mean Square 均方根
- 针对梯度下降加快迭代的优化,即反向传播的基础上,对 w,b 的优化
- 使用了指数滑动平均原理
- t: 第 t 次迭代
- dW_t^2 : 第 t 次迭代 反向传播,偏导计算得到的各个神经元的 \Delta w , 对每个元素进行 平方计算
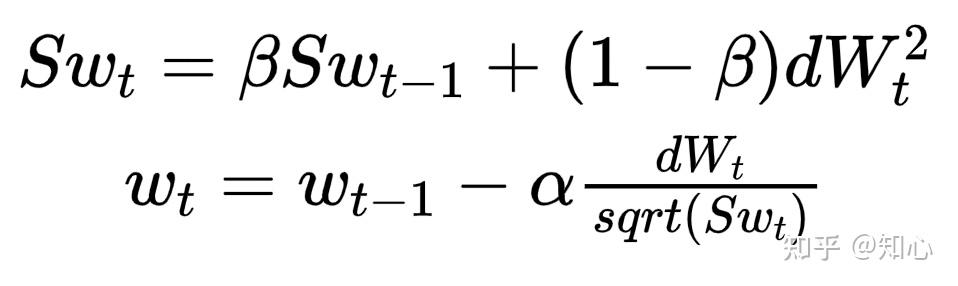
优点
- 降低 w 的更新的震荡
- 同时可以加大 学习率 \alpha
Adam
- 也是一种梯度下降优化算法,结合了 动量梯度下降+RMSprop
- 分为偏差纠正与未纠正
- 纠正主要是开始迭代时,计算更准确,随着迭代次数的增加,这个偏差不影响最后的结果
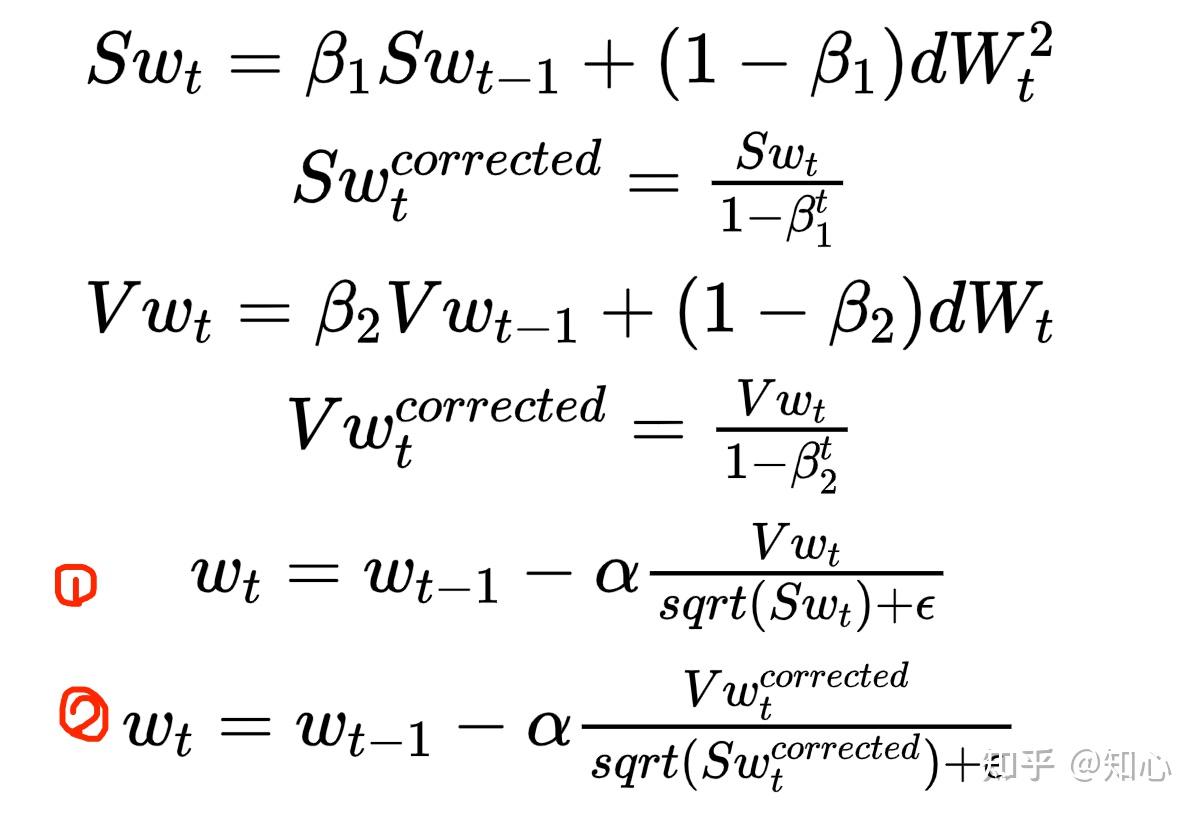
梯度优化算法优缺点
- 鞍点:一个方向最小值,另一个方向最大值,偏导 = 0
- 动量梯度下降、RMSprop 、Adam 解决了鞍点 问题,偏导不为0
- Adam解决了梯度爆炸问题,因为 \Delta w 的计算只同超参数 \alpha ,\beta_1,\beta_2 有关
- 梯度稀疏问题也适用
学习率衰减
- 学习率 \alpha 不在是固定值,而是一个变化值
- decay_rate : 衰减率
- epoch_num : 遍历所有的训练集一次,对于mini batch 而言
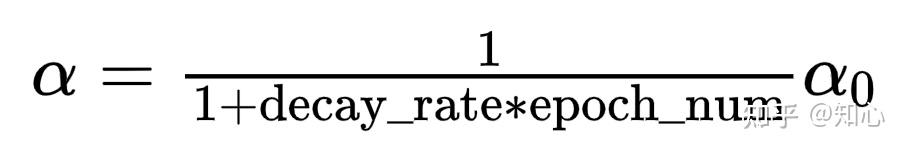
指数级衰减公式

正则化
- 佛罗贝尼乌斯范数=矩阵形式的L2范数=每层每个神经元的参数的平方和的均值
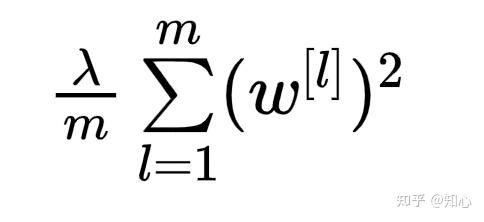
为啥可以防止过拟合
- 如果过拟合,顾忌到每个点,x很小的区间内,函数值波动比较大,对应的w的偏大;
- L2范数的情况 更新某个参数;权重衰减 0<(1- \lambda )<1,w 会更小
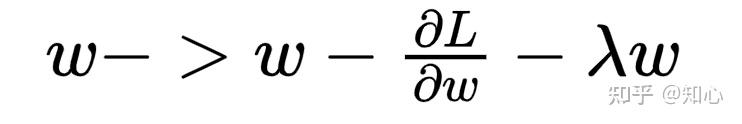
L2范数
- L1 范数;如果 w <0; sgn(w) = -1, 更新的参数w 会变大; 如果w 为正,则 sgn(w) =1 , 更新的参数w 会变小
- 降低模型复杂度;w的参数尽可能的 向0 靠齐
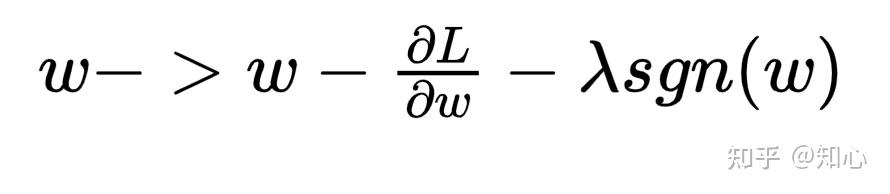
dropout
- 针对隐藏层,随机删除神经元;删除 = 神经元输出为0
- 参数更新迭代,每迭代的删除的神经元集不一样
- 删除是针对训练阶段,测试阶段不会进行删除神经元
使用了dropout,损失函数不确定
流程
- 随机选择神经元删除
- 反向传播算法,更新未删除的神经元的参数
- 再次随机选择神经元删除
- 反向传播算法,更新未删除的神经元的参数
- 继续迭代
BN Batch Norm
- 加快迭代过程
- 迭代的过程中,每个神经元的输入值的分布在变化
- 输入值分布的变化,经过 BN,限制为 均值,方差 由参数 \gamma,\beta 控制
- 降低了 网络中 前层的结构的变化 对后层的结构的影响
- 如果 是 mini batch 梯度下降,则归一化的过程中,均值和方差是有噪声的,样本有偏
- 正则化效果,如果更大的 batch 会降低正则化效果
- why BN 有正则化效果
- bn 是针对每个神经元 计算, n 个神经元,n 个 \gamma,\beta
1个神经元bn的流程
- 输入值为 x
- 线性函数 z = wx + b
- 计算 z 的 均值 \mu 和均方差 \sigma
- 转化为 均值为 0 方差为1 的 \hat{z} = \frac{z - \mu} {\sigma}
- \overline{z} = bn(\hat z) = \gamma \hat z + \beta ; 参数 为 \gamma , \beta
- 激活函数 h = h( \overline{z} )
- 如果 激活函数前 BN,则 参数 b 可忽略;可 \beta 可替代
- BN 有些在 激活函数前,有些在激活函数后,这个有争议,具体哪种更好,可以分别实验下
测试集的BN
- 1个神经元上的测试集上的BN
- 测试集上无 mini batch
- 训练的时候,1个神经元,迭代了N次,就有n 个 均值 \mu 和均方差 \sigma
- 测算 \mu 和 \sigma , 利用 指数滑动平均原理
Mini Batch + Adam + drop out + BN
计算流程 |
|



 发表于 2022-12-2 13:29:02
发表于 2022-12-2 13:29:02