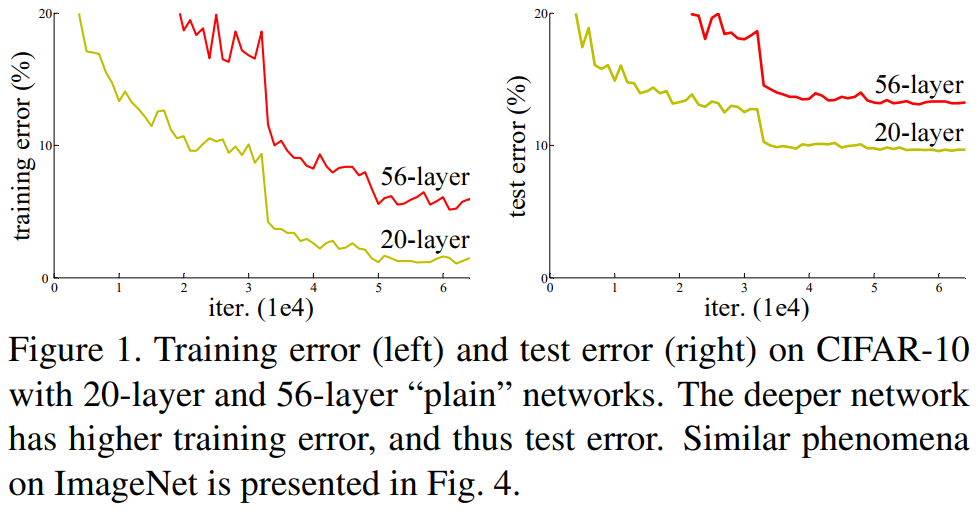
网络退化也不是梯度消失/爆炸导致的,因为梯度消失/爆炸问题很多程度上通过normalized initialization和intermediate normalization lyaers得到了解决。
如果存在某个k层的网络f是当前最优的网络,那么可以构造一个更深的网络,其最后几层仅是网络f第k层输出的恒等映射(identity mapping),就可以取得与f一致的结果;也许k还不是最佳层数,那么更深的网络就可以取得更好的结果。所以,按照常理来说,深层网络不应该表现得更差。一个合理的猜测就是,恒等映射并不是那么好学的。
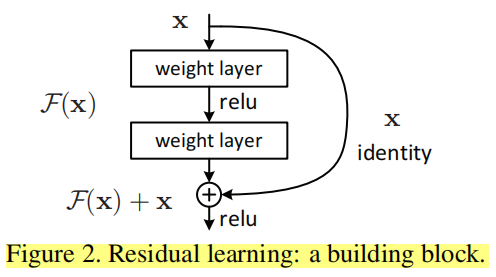
所以resnet的思想就是:不让这些stacked layers直接学习underlying mapping,而是显式地学习residual mapping。用 \rm \mathcal H(x) 表示underlying mapping,让这些层去学习 \rm \mathcal F(x) :=\mathcal H(x) - x,所以本来的要学的映射就变成了 \rm \mathcal F(x) +x (假设输入x和输出f(x)维度是相同的)。学习residual mapping比学习本来的映射要容易,极端情况下,如果恒定映射是最优的,那么it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
shortcut connections执行恒等映射,不会加任何参数和计算量
用公式表示一个building block: \rm y = \mathcal F(x,{\{\it{W}_i}\})+x , \rm x 和 \rm y 分别表示输入和输出向量, \rm \mathcal F(x,{\{W_i}\}) 表示要学习的residual mapping,像Fig2中,有two layers,那么 \rm{\mathcal F} = \it{W}\rm_2\sigma(\it{W}\rm_1x) , \sigma 为ReLU, \rm \mathcal F + x 为element-wise addition,对addition之后的结果再执行非线性激活函数。
上面公式中要求 \rm x 和 \rm \mathcal F 维度是一样的,如果不一样,就再执行一个线性映射来使维度匹配: \rm y = \mathcal F(x,{\{\it {W}_i}\})+\it{W}_s\rm x (1x1卷积来改变通道数)
层数至少为2层,如果只有一层,那就是一个线性层 \rm y=\it{W}_\rm 1x+x ,就起不到作用了。
一些实现细节
没有使用dropout
following [16],在卷积层之后使用BN(激活函数之前) conv+BN+relu
[16] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
TniL:残差网络解决了什么,为什么有效?
Residual Networks Behave Like Ensembles of Relatively Shallow Networks



 发表于 2023-1-7 18:49:53
发表于 2023-1-7 18:49:53