|
|
自从2017年 《Attention Is All You Need》[1] 提出以来,基于注意力机制的Transformer架构因其有效性,被广泛应用在包括自然语言处理、计算机视觉、以及强化学习等等各个不同的领域上,并都取得了不错的表现。
相较于原始的 MLP 架构(XW),Transformer 架构由于利用了注意力机制的归纳偏置,可以通过计算 Query 和 Key 之间的相似度来有区别地从一段序列输入中提取更加相关的信息,所以在处理信息较为离散的输入时往往能更高效地抓取到关键信息。
与之相对,MLP 架构由于缺少了这样结构化的归纳偏置,无法关注到输入中存在的共性,因此往往过于关注输入的个体特征,从而容易过拟合到训练数据上。类似地,CNN 架构更多地利用了局部性原理,关注于输入信息的局部特征,而不擅长捕获输入的长距离依赖关系。因此,Transformer 架构通常比后两者能取得更好的表现和泛化性能。
单头注意力的计算公式:
【Transformer的缺点】
在应用Transformer架构到不同类型的任务时,长文本、图像和视频等原始输入通常都会被编码为相对较长的序列。然而,Transformer架构的一个重要缺陷在于其原始的注意力机制计算时空复杂度为 \mathcal{O}(N^2) ,此处 N 为输入序列的总长度。因此限制了Transformer结构对于更长序列输入的处理能力。
【Efficient Transformers主要解决的一些问题和方式】
因此,为了解决由注意力计算的 \mathcal{O}(N^2) 复杂度带来的性能问题,并将Transformer进一步应用于更长序列输入的任务中,大量工作被提出以克服或缓解Transformer架构的这个缺点,这些工作被统称为Efficient Transformers [2]。这些工作主要利用了计算稀疏性(Sparsity)、聚类方法、注意力计算的低阶近似、引入循环连接和外部记忆模块等等方式来减少Transformer架构的计算量或增加其感受野(Receptive Feild)。
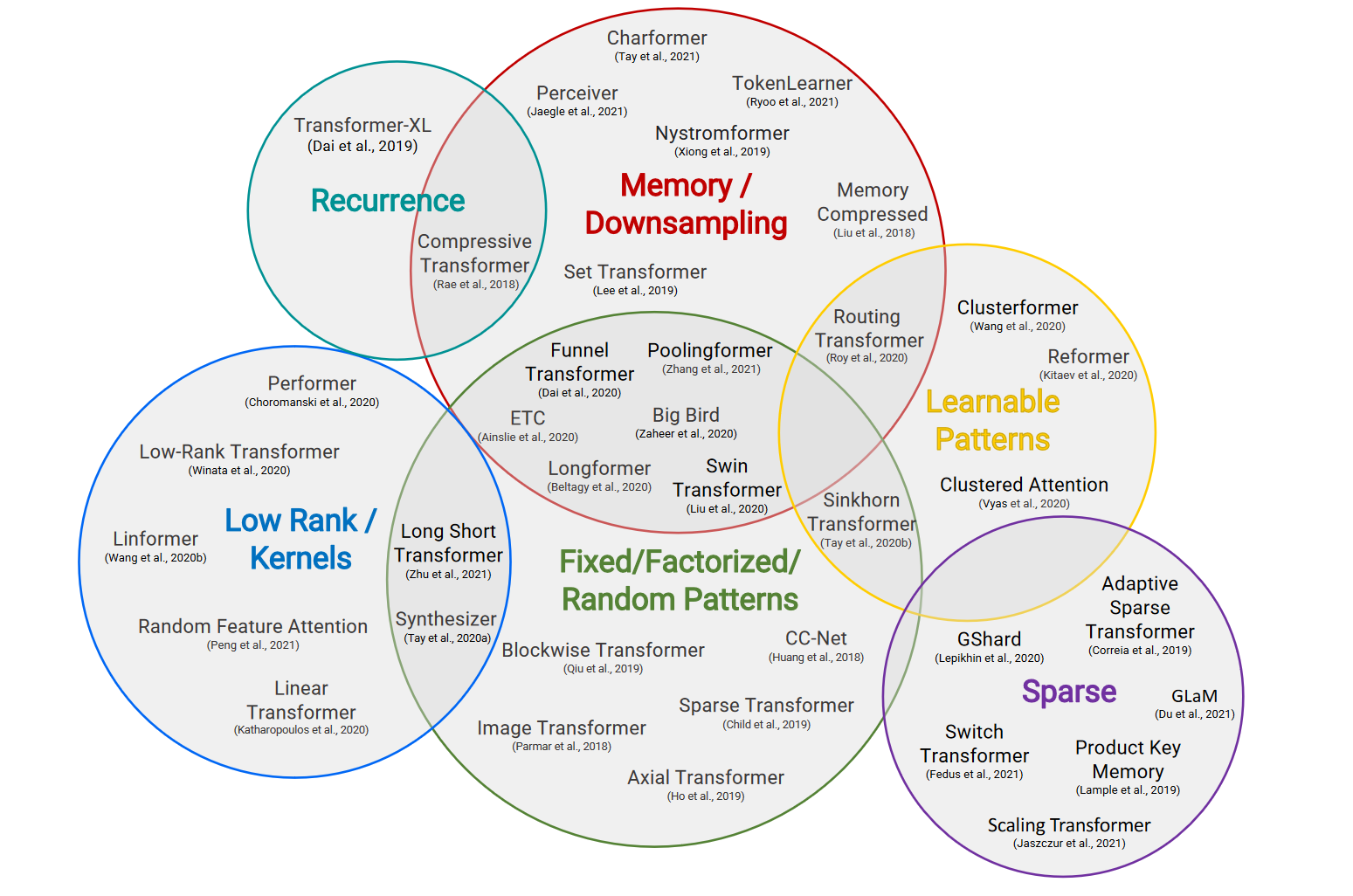
Recurrent Transformers神经网络
在Efficient Transformers中,Recurrent Transformers作为一种重点关注于解决长距离依赖(Long-Range Dependence)问题的Transformer架构,主要通过添加对过去状态或过去隐层状态的循环连接(Recurrence)实现。通过这种循环链接,模型理论上能够捕获到更大感受野内的输入信息,从而也更有可能建模这种长距离依赖关系。因此,Recurrent Transformers一般拥有更强的长序列输入处理能力和相对较低的计算开销,在一系列包括长序列文本、图像、视频、甚至深度学习等等领域的任务上有着更大的潜力。
通过这种循环链接,模型理论上能够捕获到更大感受野内的输入信息,从而也更有可能建模这种长距离依赖关系。因此,Recurrent Transformers 一般拥有更强的长序列输入处理能力和相对较低的计算开销,在一系列包括长序列文本、图像、视频、甚至深度学习等领域的任务上有着更大的潜力。
下面介绍 Recurrent Transformers 的代表工作。
Transformer-XL
Recurrent Transformers的一个代表性工作是在2019年由CMU和Google Brain提出的《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》[3]。Transformer-XL通过将长序列输入分割为固定长度的片段(Segments),使得注意力计算的窗口长度从原始序列输入的总长度减少为固定的窗口长度,从而显著减少了计算量。另一方面,为了弥补由减小的窗口长度带来的感受野损失,Transformer-XL引入了先前片段计算的隐层状态输入,尽管该缓存的先前片段的隐藏状态在训练过程中并不会被反向传播更新,但Transformer-XL通过加入了这种对先前片段的循环连接,使得其理论的感受野得到了显著提升。标准的Transformer-XL架构的最大依赖长度(Largest Possible Dependency Length)由原先的的 \mathcal{O}(N) 增加为 \mathcal{O}(N \times L) ,其中 N 为片段长度(Segment Length), L 为模型层数。
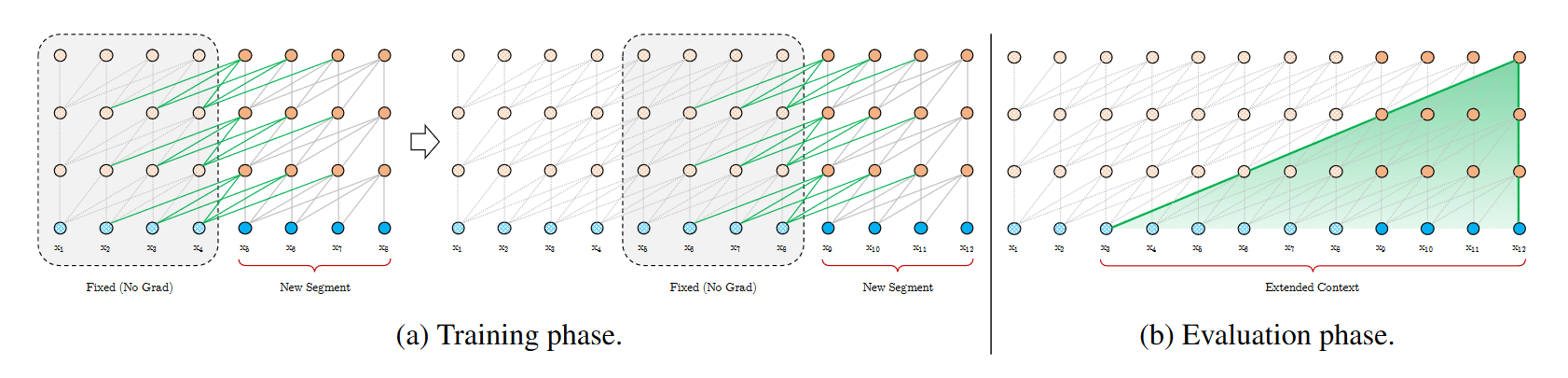
图2:片段长度N=4的Transformer-XL架构
在引入了对先前片段的循环连接后,Transformer-XL在长距离依赖的任务性能上得到了显著提升,其学到的相对有效上下文长度(Relative Effective Context Length)比同参数下的循环神经网络长80%,比标准的Transformer架构长450%,其推理速度也比标准的Transformer架构快最多1874倍。
Block-Recurrent Transformer
Transformer-XL的成功证明了Recurrent Transformers对于解决长距离依赖问题的有效性,然而其对先前片段信息的利用是被动的。由于Transformer-XL在反向传播时不会计算先前片段隐层状态的梯度,所以不能主动地根据任务需要学习更有效的先前信息表征方式。因此,为了赋予模型这种能力,2022年,Google Research和瑞士AI实验室提出了一种利用了滑动窗口注意力(Sliding-Window Attention)和LSTM机制的新架构《Block-Recurrent Transformers》[4]。
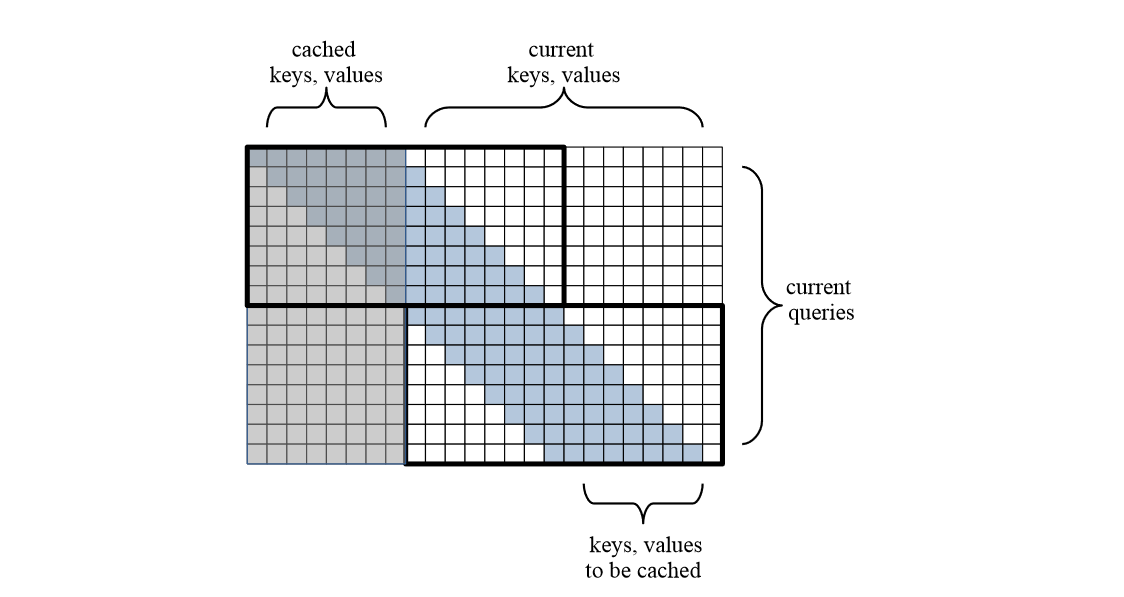
图3:片段长度N=8的Block-Recurrent Transformer滑动窗口注意力机制
Block-Recurrent Transformer首先利用了一个带Casual Mask的 N × 2N 高宽的滑动窗口注意力机制来使得每一个Token在计算的时候都能注意到前 N-1 个Tokens,此处 N 为块(Block)长度。这相比固定片段切分的原始Transformer架构拥有了2倍的平均上下文长度(Average Context Length),并且较好地解决了由于固定片段切分导致的语义不连续问题。由于每一层注意力块都能最多注意到前 N 个Tokens,所以Block-Recurrent Transformer架构的理论感受野也是 \mathcal{O}(N × L) 。另一方面,相比于Transformer-XL的 N × N 高宽的固定窗口注意力,扩大的窗口宽度允许反向传播计算先前块的隐层状态的梯度,所以模型在学习长序列输入时具备了主动学习先前块信息表征方式的能力。
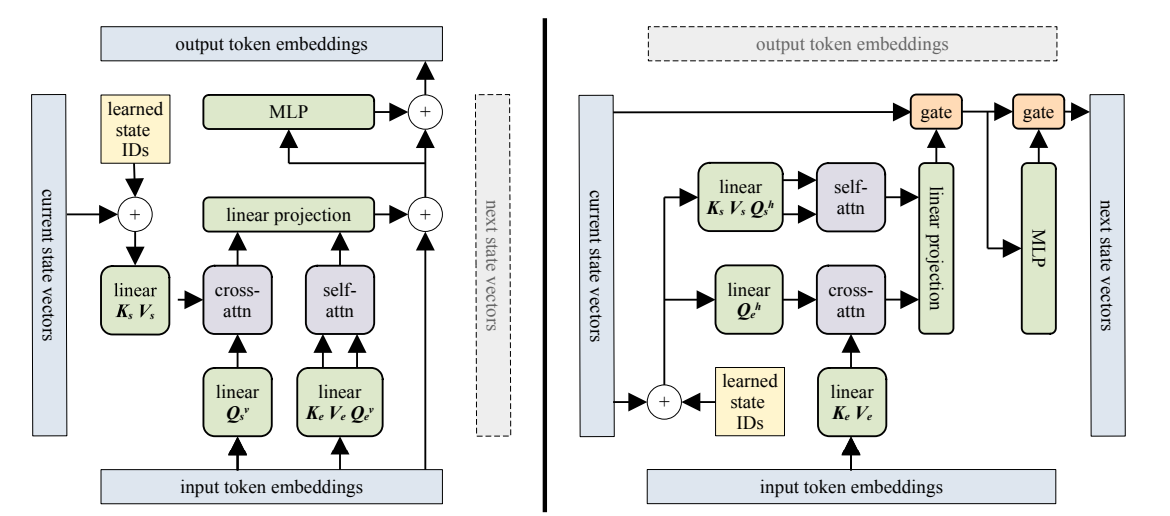
图4:层级连接(垂直)和循环连接(水平)两个方向上的Block-Recurrent Transformer架构
为了进一步加强模型对长距离依赖的建模能力,在不显著增加训练和推理速度的情况下,Block-Recurrent Transformer额外引入了记忆门和遗忘门来显式地控制块间循环状态(Recurrent State)的输入和更新。LSTM循环连接的加入使得模型的感受野从原本的 \mathcal{O}(N × L) 进一步扩大为理论上无穷大,因此在长距离依赖建模任务上有更大的潜力。论文中测试了多种不同的门设计和连接方式,以及循环状态的连接方式,以找到效果最佳的配置方式。实验结果表明Block-Recurrent Transformer在长序列语言建模的表现和训练速度上都进一步超越了Transformer-XL。
Recurrent Transformer在RL领域的一些应用
Recurrent Transformers 通过添加对过去状态或过去隐层状态的循环连接,能够观察到理论上更大感受野内的输入信息,因此更能捕获并建模这种长距离依赖关系。在更长的序列输入,包括长文本、视频输入,以及长轨迹的强化学习任务场景中,Recurrent Transformers 都期望有更高的表现和训练效率。
比如,在OpenAI 2022年的工作《Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos》[5]中,论文使用了Transformer-XL架构在有动作标注的Minecraft游戏视频数据集上训练了一个非因果(Noncausal)的逆动力模型(Inverse Dynamic Model)来预测Youtube视频中玩家在Minecraft游戏中执行的动作。之后,论文使用因果(Causal)的Transformer-XL架构,用逆动力模型标注的伪动作标签数据进行模仿学习和强化学习微调,在Minecraft游戏中第一个成功制作了钻石工具。
展望
Recurrent Transformers 在自然语言处理任务上的成功证明了 Recurrent Transformers 对于解决长距离依赖问题的有效性。
对于包括长文本、视频以及长轨迹的强化学习环境等各种长序列输入的任务上,Recurrent Transformers 都表现出了很好的效果。然而,目前现有的 Recurrent Transformers 尚未完全凸显循环连接的优势。
譬如,在 Block-Recurrent Transformers 中,作者测试了各种不同的控制门设计和循环连接方式,却并未在更灵活的控制门上取得更好的结果。
另外,在训练过程中,模型可能会忽视循环连接的作用,退化为无循环连接的 Transformer-XL 架构。因此,Recurrent Transformers 在各个领域上的研究和应用仍有着非常大的空间。
Reference
[1] A. Vaswani et al., “Attention Is All You Need.” arXiv, Dec. 05, 2017. doi: 10.48550/arXiv.1706.03762.
[2] Y. Tay, M. Dehghani, D. Bahri, and D. Metzler, “Efficient Transformers: A Survey.” arXiv, Mar. 14, 2022. doi: 10.48550/arXiv.2009.06732.
[3] Z. Dai, Z. Yang, Y. Yang, J. Carbonell, Q. V. Le, and R. Salakhutdinov, “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context,” Jan. 2019, doi: 10.48550/arXiv.1901.02860.
[4] D. Hutchins, I. Schlag, Y. Wu, E. Dyer, and B. Neyshabur, “Block-Recurrent Transformers.” arXiv, Mar. 11, 2022. Accessed: Jul. 08, 2022. [Online]. Available: http://arxiv.org/abs/2203.07852
[5] B. Baker et al., “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos,” p. 34. |
|



 发表于 2023-1-14 14:45:35
发表于 2023-1-14 14:45:35