|
|
日常数据分析中,词频分析是一个很好的文本挖掘方法,这篇文章说说词频分析方法。
这里选用京东商场中购买手机的部分数据信息,利用jieba词库对购物评论进行分词,提取客户群体对手机的关注点。
数据集来源:https://www.kesci.com/home/project/5ece06fb12fba90036cf26bd/dataset
1.导出所需库
#导入所需基本包
import pandas as pd
# 导入扩展库
import re # 正则表达式库
import jieba # 结巴分词
import jieba.posseg # 词性获取
import collections # 词频统计库2.导入文件
#导入数据集
data = pd.read_csv('C:/Users/dwhyx/Downloads/data/京东评论数据.csv')
#查看数据基本情况
data.info()
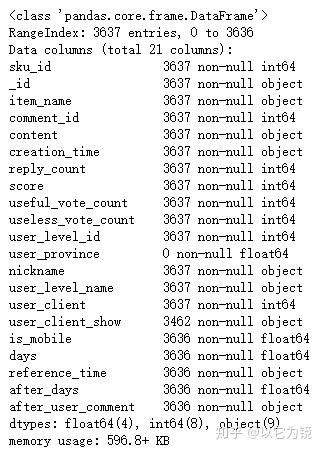
共21个字段,基本上购物平台后台基本字段,如:sku_id,item_name(商品名称),content(评论),creation_time(创建时间),其中content是我们本次主要分析对象。
#预览文件,展示前3行
data.head(3)
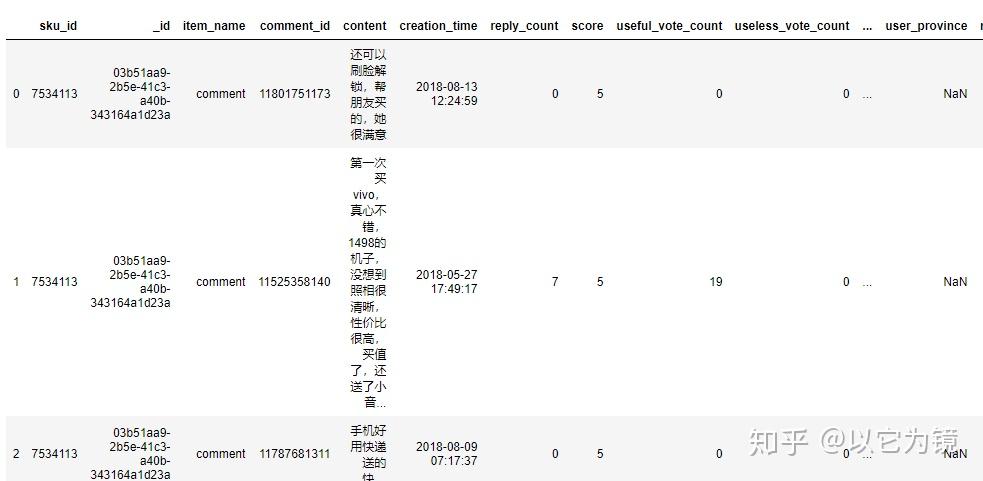
通过对文件预览,可以对整个数据集有更加直观了解。(若对本数据集涉及的字段比较熟悉,可以省略,这里方便第一次接触网购后台数据的同学)
3.合并文本单元格
content= ("".join(i for i in data['content'])) #利用循环语句合并文本这里只分析首次评论(content),暂不考虑用户追加的评论(after_user_comment)。
4.文本处理
#预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|\ |"') # 定义正则表达式匹配模式(空格等)
string_data = re.sub(pattern, '', content) # 将符合模式的字符去除
#文本分词
seg_list_exact = jieba.cut(string_data, cut_all=False, HMM=True) # 精确模式分词+HMM
object_list = []
#获取停用词
with open(r'C:/Users/dwhyx/Downloads/data/中文停用词库.txt', encoding='gbk') as file:
stopwords = [x.strip() for x in file.readlines()]
#去除停用词(目的是去掉一些意义不大的词)
for word in seg_list_exact: # 循环读出每个分词
if word not in stopwords: # 如果不在去除词库中
object_list.append(word) # 分词追加到列表5.词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
word_counts_top = word_counts.most_common(100) # 获取前100个最高频的词
print(word_counts_top)输入结果如下:

如果想把结果保存为Excel表格,可以将字典形式转化为列表,写入Excel。
import csv
Excel = open("评论词频分析.csv", 'w', newline = '') #打开表格文件,若表格文件不存在则创建
write = csv.writer(Excel) #创建一个csv的writer对象用于写每一行内容
write.writerow(['词语','出现次数']) #写表格表头
item = list(word_counts.items()) #将字典转化为列表格式
item.sort(key = lambda x: x[1], reverse = True) #对列表按照第二列进行排序
for i in range(100):
write.writerow(item) #把前100词语写入表格
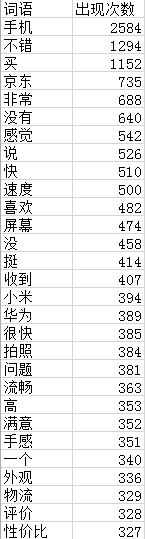
Excel只截取部分
6.词频分析
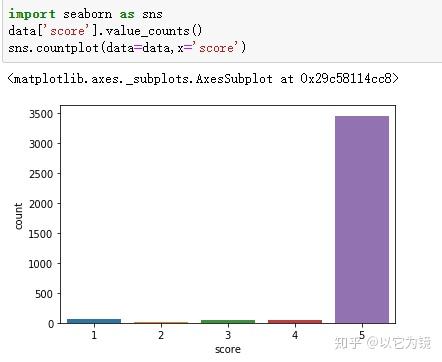
从前100个高频关键词中看出,“不错”出现了1294次,说明这批手机订单客户评价对商品较为满意。这点也可以结合数据集中score(评分)字段,绘制直方图发现5分好评占绝大部分。
其次,我们能看出“速度”、“屏幕”、“电池”、“好看”、“内存”、“质量”、“摄像头”等高频词语,说明客户对手机运行的速度,电池容量大小,手机外观、内存等配置还是比较在意的,厂商可以针对这些客户的关注点,更好的改进、优化。
最后,评论中出现“小米”、“华为”、“苹果”等字眼,因为本数据集item_name(商品名称)已脱敏,不太清楚具体每个订单销售的手机品牌,评论中出现各手机品牌,可能是本订单是相关品牌手机,也有可能评论中与其他手机品牌对比。我们可以通过关键词匹配,查询具体评论内容,进行浏览阅读,这里以搜索“小米”相关评论内容为例。
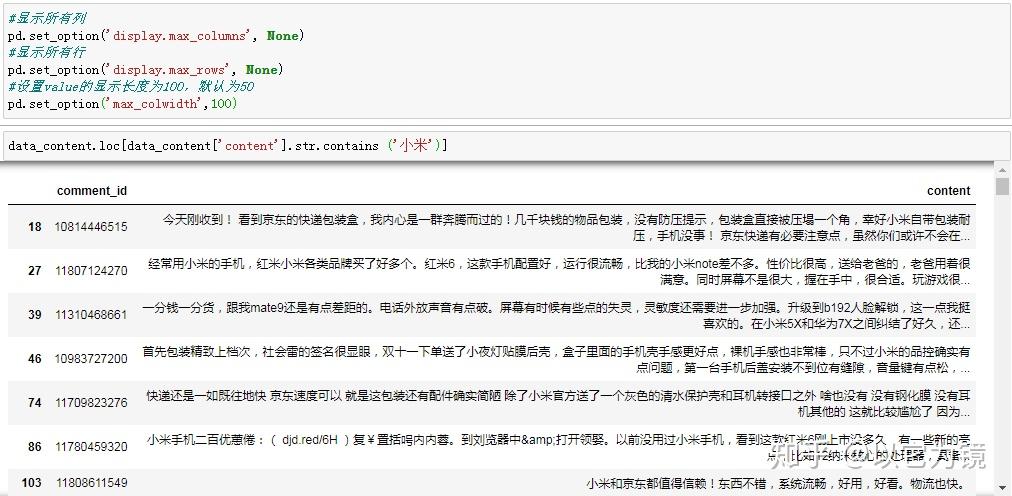
为了让print内容完全展示,便于阅读,可以对pandas展示列表进行设置
总结
词频挖掘分析在运营中用处很多,比如,某款新上产品,想要了解新产品具体情况,可以跟踪分析发布后一个月的app评论或网上爬取贴吧论坛等相关文章,分析客户的关注点和反馈比较多的问题,针对客户关注点可以侧重的优化,对反馈比较的问题优先解决。运营中也可以根据时间序列对评论进行分析,分析运营过程中客户关注点的变动,及时把握客户心理等变化。毕竟市场是检验需要的唯一标准。
相关文章:
以它为镜:舆情情感分析
以它为镜:利用Python分析《隐秘的角落》中的人物网络关系 |
|



 发表于 2022-12-12 05:54:31
发表于 2022-12-12 05:54:31